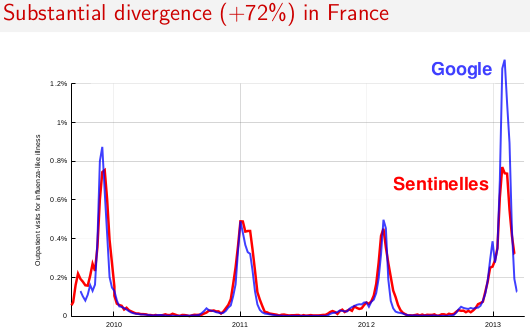
Summary: At this point [Feb. 4, 2013], it appears likely that Google Flu Trends has considerably overstated this year's flu activity in the U.S. But we won't be able to draw a firmer conclusion until after the flu season has ended. I don't know why the model broke down this year but am eager to learn, when and if Google comes to a similar conclusion. For now, I suspect this episode may provide a cautionary tale about the limits of inference from "big data" and the perils of overconfidence in a sophisticated and seemingly-omniscient statistical model.
I am not an expert on the flu and you should not make health decisions based on Quora. You should get vaccinated, wash hands often, cover a cough, stay home from work if sick, and follow the CDC's advice: Seasonal Influenza (Flu).
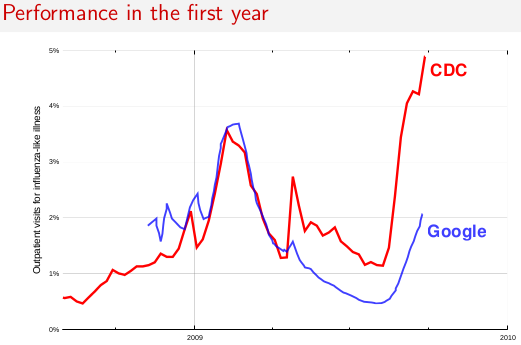
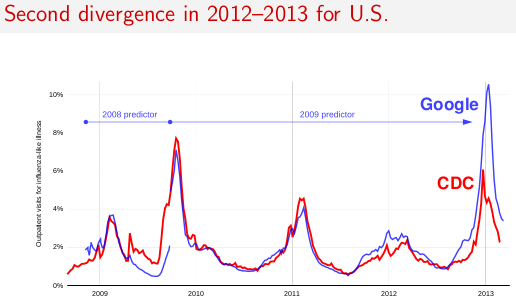
Here are the nationwide figures Google Flu Trends has estimated since its launch, and the underlying CDC index it tries to predict:

By contrast, on Jan. 20 Google had finalized its prediction for the same statistic: 10.6%. This 6.0-percentage-point difference is larger than has ever occurred before.
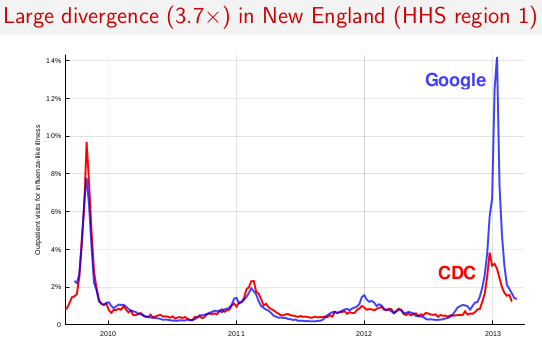
For that week, in eight out of the ten HHS regions, Google's predictor was more than double the CDC's figure. (For example, here in New England where I am, Google was saying 14.2% of doctor visits were for influenza-like illness, vs. a CDC figure of only 2.9%.)
Google's scientists quite properly point out that the CDC will adjust its data retroactively, as more data comes in for past weeks. Thus the "red line" on the above graph can change over time, whereas the "blue line" is locked down in all but its very last data point. However, the CDC's adjustments have been modest so far, and even for recent weeks where the Google-CDC divergence is very large, the total number of sites reporting to the CDC has now reached close to the most it ever hits. Further dramatic revision of those data points seems unlikely.
In my nonexpert view, at this point there is little chance that Google Flu Trends's estimates can somehow be vindicated. A similar episode happened in 2009, causing the previous tweak seen above. Some of their approach may need to change if they want these divergences, repaired only after the fact, to happen less often.
Why the model did not work this year is an exciting mystery, and I am eager to learn the answer, when and if Google reaches a similar conclusion that something went awry.
- Did one or two of the 160 search queries dramatically increase in popularity? Or was the effect seen over all 160 queries used in the model?
- Did Google's decision not to retrain the model since 2009 make the difference? If they had retrained the model knowing what they knew in mid-2012, would this season's estimates have been better or worse? Were there hints last summer that, in retrospect, suggest they were mistaken not to retrain the model, and if so can those hints improve the decision process for retraining in the future?
- Can we evaluate the effect of different retraining policies (e.g. retrain every year, retrain every month vs. the current policy of retraining only on certain triggers), and how they balance various risks? What should the triggers be?
- Is it possible to estimate flu intensity using queries chosen by a computer without human intervention for their retrospective accuracy? Would the predictions be better if humans intervened to make sure every query made sense as a flu predictor? Or would this simply introduce more problems?
The promise of real-time disease-activity estimates is a valuable idea that has the potential to save lives. Google is the most sophisticated company in the world at this kind of inference, and the fact that even they can apparently stumble suggests that this is really, really tricky. I hope Google improves their technique and continues to attempt it. I'm happy to help them in any way if they could use it, but I doubt they will need me.
===
My graph above may yield a different impression from Google's own graph of their performance, at http://www.google.org/flutrends/about/how.html . That graph looks like this:

- The graph shows a "hindcast" from Google's "2009" Flu Trends predictor, the one launched in September 2009 just after the end of the plot. No data point on this graph was actually displayed to the public as a contemporary estimate. From the launch in November 2008 until the end of this plot, Google displayed predictions from the "2008 algorithm." The data from that algorithm is no longer available from Google's site; I had to trace it from a bitmap image that Google submitted in a scientific paper to PLoS ONE about the algorithm's difficulties in 2009 and subsequent improvements (Assessing Google Flu Trends Performance in the United States during the 2009 Influenza Virus A (H1N1) Pandemic).
- The graph is almost entirely of training data; in other words the CDC data that was used to design the 2009 Google algorithm. It could avoid some confusion if Google were clearer about how much of this graph was actually predicted, versus information that the algorithm was given going in. That would look like this:

- The plot ends at the launch of the current algorithm and hasn't been extended to the present. In other words, every single data point in my plot above is missing from Google's plot, and none of the data points on Google's plot are on my plot. In my view, the important thing is the prospective performance of the Google Flu Trends system as it actually estimated the flu. This is the exact opposite of what Google, with its own plot, implicitly expresses it thinks is the relevant figure of merit. (I'm not saying they really believe this; just what the graph says to me.)
- Although the data shown is from the "2009" algorithm, the only reference Google gives is to their earlier scientific paper about the 2008 algorithm, published in "Nature" (http://research.google.com/archive/papers/detecting-influenza-epidemics.pdf). There is no mention of the later paper or the change in algorithm.
- In the Nature paper, Google reported that the 2008 algorithm had a 97% mean correlation with the CDC data on a held-out verification set, which is a fantastic result (even higher than the 90% that Google had achieved on their own training set!). In the PLoS ONE paper, published three years later in a less prestigious venue, Google reported that the 2008 algorithm's actual correlation with the first wave of early-2009 "swine flu" was only 29%. I have heard cynics hyperbolize that the purpose of Nature is to publish fantastic-seeming results so that they can be debunked under subsequent scrutiny by less-prestigious journals. It's depressing to see a case where that was somewhat realized.
- Although Google wrote in the PLoS ONE paper that "We will continue to perform annual updates of Flu Trends models to account for additional changes in behavior, should they occur," and a similar statement in the Nature supplement, in practice Google has not updated the algorithm since September 2009. As they write below, they determined that an update wasn't necessary. But they could make this more clear -- as well as discussing how they determine whether or not to update the model -- in their papers and Web site.

The fact that Google decided not to update the model for 2012-13, and subsequently the model performed poorly in 2012-13, suggests that the procedure for deciding when an update is necessary may need to be reworked. On the other hand, it's possible that even if Google had updated the model, the divergence would have been just as bad (or worse). The difference may mean different things for how Google Flu Trends can be improved in the future. These are questions I sincerely hope Google examines and answers in a future scientific paper or Web site update.
Thank you for the useful article. It has helped a lot in training my students. Keep writing more.
ReplyDeletebest big data training in Chennai
Great ARticle
ReplyDeleteJava Online Course | Java Training in Chennai | Java Training Institutes in Chennai
Great Article
Java Online Course | Java EE Training
Java Training Institutes in Chennai | java j2ee training institutes in chennai | Java Training in Chennai | J2EE Training in Chennai | Java Course in Chennai
Java Interview Questions | Java Training Institutes | Core Java Interview Questions
Buzz Applications is offering website for your product or your company!!
ReplyDeleteI am following your blog from the beginning, it was so distinct & I had a chance to collect conglomeration of information that helps me a lot to improvise myself.
ReplyDeleteRegards,
CCNA Training in Chennai | CCNA Training Institute in Chennai | Best CCNA Training in Chennai
That is it! You are currently sending SMS upgrades!SMS Marketing Applications On the off chance that you need to change settings and alter the SMS messages that are sent, keep perusing.
ReplyDeleteI learned some new information. Thanks for sharing.
ReplyDeleteMagento Development in Chennai
My Arcus offer java training with 100% placement. Our java training course that includes fundamentals and advance java training program with high priority jobs. java j2ee training with placement having more exposure in most of the industry nowadays in depth manner of java
ReplyDeletejava training in chennai
ReplyDeleteuseful information
Online recruitment for bank jobs and government jobs and you can get Notification and application to apply online for bank jobs and govt jobs
GK Updates (GK), Latest Current Affairs, General knowledge, Current Affairs, Daily Current Affairs, GK, Todays GK, Daily GK Updates,This Year Latest Current Affairs, India Current Affairs GK, General, Knowledge, Quiz, Awareness, Questions, Answers, Explanation, Interview, Entrance, GK,Exams.
ReplyDeleteEXcellent posts thanku for sharing..
ReplyDeleteSAP Hana training in hyderabad
Thakui for sharing..
ReplyDeletesap fiori training
Great article. Keep sharing such a informative post.
ReplyDeleteweb designing institute in chennai
Great article. Glad to find your blog. Thanks for sharing.
ReplyDeleteweb designing training in chennai
Nice Information:
ReplyDeleteTelugu Cinema Contains Telugu Cinema News, Latest Movie Reviews, Actor, Actress, Movie Galleries And Many More Telugu Cinema News
The Google Apps Marketplace is another online store for incorporated business applications that permits Google Apps clients to effortlessly find You can now customize your Google .com with a foundation picture. https://800support.net/google-latest-news/googles-new-launch/
ReplyDeleteNice Information
ReplyDeleteios Training in Chennai
this is very use full information.....and thanks for sharing....
ReplyDeleteqlikview Training in Chennai
Useful Information……
ReplyDeletemsbi training in chennai
Nice Information......
ReplyDeletesas-predictive-modeling training in chennai
ReplyDeleteOur Complete in depth Java training course takes you to TOP Level IT companies with high end package. Arcus Offers Java J2EE real time training with placement assurance..
java training in chennai
Thank you so much for sharing this useful information. ETL Testing Online Training is excellent solution for learning from home MSBI Online Training
ReplyDeleteI use this service https://www.intistele.com/blog/get-started-with-sms-marketing/ when I need to address several issues that are important to keep in touch with the client, not to lose it. Often I am using discounts on birthday. A good tip to stimulate demand.
ReplyDeleteMettur dam updates Mettur Dam
ReplyDeleteMettur dam updates Mettur
شركة تسليك مجاري المطبخ بالرياض
ReplyDeleteشركة تسليك مجاري بالرياض
شركة تسليك مجارى الحمام بالرياض
level تسليك المجاري بالرياض
افضل شركة تنظيف بالرياض
تنظيف شقق بالرياض
شركة تنظيف منازل بالرياض
شركة غسيل خزنات بالرياض
افضل شركة مكافحة حشرات بالرياض
رش مبيدات بالرياض
شركة تخزين عفش بالرياض
شركة تنظيف مجالس بالرياض
تنظيف فلل بالرياض
ابى شركة تنظيف بالرياض
it is very usefull inforamation thanq..telugubullet.com also a super site for latest telugu news updates.
ReplyDeleteIf you are really looking for a genuine advice and suggestion for Yahoo issues, you can dial a Yahoo Customer Care to have any kind of suggestion. Their suggestions and advices are free, so you can find any time with their toll-free number.
ReplyDeletean article in Science magazine titled The Parable of Google Flu: Traps in Big Data Analysis exposed Flu Trends’ use of faulty data collection methods for the 2012-2013 flu season. The article called the program “big data hubris,” for overestimating doctor visits for the flu compared with CDC reports.
ReplyDelete“Quantity of data does not mean that one can ignore foundational issues of measurement and construct validity and reliability and dependencies among data. The core challenge is that most big data that have received popular attention are not the output of instruments designed to produce valid and reliable data amenable for scientific analysis,” the authors of the Science magazine wrote, which led to dozens of media reports questioning the relevancy of Flu Trends.
http://kosmiktechnologies.com/msbi/
Thanks for sharing the Informative article.
ReplyDeletehttp://kosmiktechnologies.com/msbi/
Awesome post.
ReplyDeleteI read your blog everything is helpful and effective.
Thanks for sharing with us.
Java Training in Chennai
Nice Post keep updating like this,
ReplyDeletetelugu 2015 movies
Nice information. It looks very informative informations to us. I have to forward your blog to my friends. keep sharing. Thank you. Hadoop Training in Chennai | Android Training in Chennai | Python Training in Chennai
ReplyDeleteGmail provides great customer service to help its customers solve all types of Gmail related problems. The technical help at Gmail provide best solutions to users for variety of problems that they face from time to time. The technical problems create trouble in using the Gmail account smoothly and this disrupts the work of the Gmail users.
ReplyDeleteYour blog is very interest about the Google Flu Trends, Perfectprofile.net is a leading Job Portal in india. if you want etl testing jobs in hyderabad please go through this website.
ReplyDeleteThis comment has been removed by the author.
ReplyDeletereally you have shared very informative post. the post will be helpful to many peoples. thank you for sharing this blog. so keep on sharing such kind of an interesting article.
ReplyDeletepython training in chennai
I understand the trends of google flu trends.This blog is very useful to me.The information you provide is very nice.Thanks for sharing.
ReplyDeleteSAS Training in Bangalore
Thanks for this valuable information.I was really learn about content.If you want walk-ins in hyderabad for etl testing fresher’s.check this site.
ReplyDeleteIn short you would always get help for any type of trouble from the Gmail technical support team and the number is available toll free globally around the world.
ReplyDeleteThe Gmail customer service number is available round the clock for any type of help that you want. The number is global and is easily available round the clock from any place
Have you ever undergone the ordeal of waiting for the technical support from the yahoo tech support engineers? Such things are not the characteristic features of yahoo customer service. Yahoo customer service is not the newly born component of yahoo .From the very beginning, yahoo customer service has been very much integral to yahoo services. From time to time, certain changes and improvements have been introduced to yahoo customer service with a view to meet the changing needs of the yahoo users. So, if you are a yahoo user, you are certainly fortunate enough to have the yahoo support professionals always available at your closest disposal.
ReplyDeleteIn case you are not able to give the permanent fix to the particular issue, you need to immediately dial Gmail customer support 1-800 phone number for live chat. The phone number will give the quick response for the particular trouble in your Gmail account. Just get in touch with Gmail customer care experts and obtain the splendid solution.
ReplyDeleteHello I am so delighted I located your I really located you by mistake, while I was watching on google for something else, Anyways I am here now and could just like to say thank for a tremendous post and a all round entertaining website. Please do keep up the great work.
ReplyDeleteIn case you are using Gmail account for quite a longer period of time and confront an issue in downloading emails on your smart device, you don’t need to get worried at all. For the particular trouble, you need to call Gmail customer care 800 telephone number anytime.
ReplyDeleteI really enjoy simply reading all of your weblogs. Simply wanted to inform you that you have people like me who appreciate your work. Thanks ..
ReplyDeletePython Training in Chennai | Big Data Analytics Training in Chennai
Role of education, its failer to deliver equal oppurtutiny to women.http://www.how-todo.xyz/
ReplyDeleteIn case if your Yahoo email account is not working responding properly and you are finding for instant resolution then you can rely on us. Simply pickup your phone and dial Yahoo customer service helpline number which is toll-free.
ReplyDelete"Forgot account password" is a very common issue which almost every email users have faced once in the lifetime. If you forgot password for your Yahoo mail account, you can easily retrieve your password by using the Yahoo password assistance page.
ReplyDeleteHi, I have read your blog. Really very informative and excellent post I had ever seen about Python. Thank you for sharing such a wonderful blog to our vision. Learn Python Training in Chennai to know more details about this technology.
ReplyDeleteWeb Designing Training in Chennai|Big Data Analytics Training in Chennai
This information useful who search for CCNA jobs in Hyderabad .So we need this information.Thank you for sharing this great post.
ReplyDeleteHi admin.., I read your blog completely.I Gather lot of information in this blog that information will help me develop my knowledge. Thanks for sharing. keep sharing more blogs.
ReplyDeleteCore Java Online Training
Skype is very useful and power full software and it will be good for personal or official work. You can use Skype for texting, sharing data, audio call, video call, video conferencing and much more or If you want skype setup in your window 10. Than this is your guide. If you face any problem don’t worries! contact with us and visit our website us they are available 24*7 to help.
ReplyDeleteSkype application is well known for its variety of quality features. One of the most interesting features that Skype offers is Group chats. It allows making group video chats with up to 25 persons at a time.Our experts can be contacted via our toll-free number, email and live chat as well. Moreover, our communication lines are open 24 hours. So, feel free to get in touch with Skype Support Team or Skype Live Chat . We assure to serve you with utmost quality services.
ReplyDeleteIf you're unable to merge your Pages, it means that your Pages aren't eligible to be merged. And if you don’t have any solution to facebook page merge so doesn’t worry we help you to solve this problem visit our website or contact with contact service team.
ReplyDeleteIt was a wonderful chance to visit this kind of site and I am happy to know. thank you so much for giving us a chance to have this opportunity! I will be back soon for updates.click here
ReplyDeleteI have read your blog and I gathered some needful information from your blog. Keep update your blog. Awaiting for your next update.
ReplyDeleteSAS Online Training
R Programming Online Training|
Tableau Online Training|
Really fantastic. you are really a skilled blogger.I like your post very much.Thanks for sharing.keep sharing more blog.
ReplyDeleteWhite Label Website Builder
This is one of the main things you can do and also one of the most important things you can do. google dashboard
ReplyDeleteYour new valuable key points imply much a person like me and extremely more to my office workers. With thanks; from every one of us.
ReplyDeleteselenium training in chennai|
Needed to compose you a very little word to thank you yet again regarding the nice suggestions you’ve contributed here.
ReplyDeleteJava Training in Bangalore
I feel really happy to have seen your webpage and look forward to so many more entertaining times reading here. Thanks once more for all the details.
ReplyDeletehttp://www.traininginmarathahalli.in/amazon-web-services-training-in-bangalore/
Thanks for one marvelous posting! I enjoyed reading it; you are a great author. I will make sure to bookmark your blog and may come back someday. I want to encourage that you continue your great posts, have a nice weekend!
ReplyDeleteJava Training in Chennai
Java Training in Bangalore
Java Training in Bangalore
Thanks for everything. Anybody who wants support for Facebook related issues, call at Facebook contact number 1 (407) 965-2136.
ReplyDeleteWow, I'm really impressed by this website, not only does it look good, the posts are super interesting too! Subscribed! By the way, if you need hep with singapore company incorporation, let us help, we are the best business incorporation assistant. register a business immediately!
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteAll of Facebook password reset issues can be solved with us at 8663243042. Visit http://www.facebookhelp.us
ReplyDeleteThis comment has been removed by the author.
ReplyDelete
ReplyDeleteIt has been simply incredibly generous with you to provide openly what exactly many individuals would’ve marketed for an eBook to end up making some cash for their end, primarily given that you could have tried it in the event you wanted.
https://www.besanttechnologies.com/training-courses/data-science-training-in-bangalore
https://www.besanttechnologies.com/training-courses/data-warehousing-training/datascience-training-institute-in-chennai
Your good knowledge and kindness in playing with all the pieces were very useful. I don’t know what I would have done if I had not encountered such a step like this...Hadoop Training in Chennai
ReplyDeleteAwesome website with awesome articles keeps up the good work.Online Coursework Help
ReplyDeleteThis blog is very helpful for beginners and experts also, thanks for sharing it. Keep share content on MSBI Online Training Hyderabad
ReplyDeleteExcellent article. Very interesting to read. I really love to read such a nice article. Thanks! keep rocking.
ReplyDeleteSeo Companies in bangalore
low cost seo plans
Online Marketing Services in bangalore
Thanks for your information sharing with us, We are waiting for your more updates on MSBI Online Training Hyderabad
ReplyDeleteI found your this post while searching for some related information on blog search...Its a good post..keep posting and update the information. promote website
ReplyDeleteHi There,
ReplyDeleteThank you! Thank you! Thank you! Your blog was a total game changer!
If you have any idea about that and you have the secure and efective way to send files through socket I'll appreciate that.
This the code that I am using, it works well for the small files, but for the big ones don't work
Great effort, I wish I saw it earlier. Would have saved my day :)
Gracias
Uday
Thanks for your valuable answer. I clearly understand about google flu trends with your answer. Thank you.
ReplyDeleteBest PHP Training in Chennai | Best PHP Training Institute in Chennai
why would you know anything about how Google marketing lists your website, social media, pay-per-click, YouTube and others can play a critical role in your business? https://edkentmedia.com/ppc-management-toronto/
ReplyDelete
ReplyDeleteI believe there are many more pleasurable opportunities ahead for individuals that looked at your site.
Selenium Training in Porur
Thank you for your great post.
ReplyDeleteInformatica Training in Chennai
Informatica Course in Chennai
I feel really happy to have seen your webpage and look forward to so many more entertaining times reading here. Thanks once more for all
ReplyDeletethe details.
white label website builder
Well Said, you have furnished the right information that will be useful to anyone at all time. Thanks for sharing your Ideas.
ReplyDeleteMagento course in chennai
I wish to show thanks to you just for bailing me out of this particular trouble.As a result of checking through the net and meeting techniques that were not productive, I thought my life was done. JAVA Training in chennai
ReplyDeleteVery Nice Blog I like the way you explained these things.
ReplyDeleteSalesforce Training in Hyderabad
Salesforce Admin Training in Hyderabad
nice post and i like to read your unique content, Thanks for the best blog.it was very useful for me.keep sharing such ideas in the future as well.this was actually what i was looking for,and i am glad to came here
ReplyDeleteagen dominoqq terpercaya
BwinQQ.casino agen dominoqq terpercaya
BwinQQ.casino situs dominoqq terpercaya
BwinQQ.casino situs poker online terpercaya
BwinQQ.casino agen poker terpercaya
bandarqiu99.info situs domino99 terpercaya
Mrjudibola.com agen bola terpercaya
Mrjudibola.com Bandar bola terpercaya
Daftar Poker Online
Poker Online Indonesia
Thank you for this Useful Blog!
ReplyDeleteVlsi projects in Chennai | Robotics projects in chennai
Very usefull information to everyone thanks for sharing
ReplyDeleteSalesforce Lightning Online Trainig Hyderabad
Best Amazon web Services Training Hyderabad
It is nice post.For More information visit our website
ReplyDeleteFinal Year Iot Project Centers Chennai | ME Projects Chennai
I have read your blog its very attractive and impressive.I like it your blog.
ReplyDeleteData Mining Project Centers in Chennai | Secure Computing Project Centers in Chennai.
Thanks for the great info you post!
ReplyDeleteIEEE Electrical Projects in Chennai | IEEE Php Projects in Chennai.
This comment has been removed by the author.
ReplyDeleteYour posts is really helpful for me.Thanks for your wonderful post. I am very happy to read your post. It is really very helpful for us and I have gathered some important information from this blog.
ReplyDeleteJava Training in Chennai | Java Training Institute in Chennai
This was an nice and amazing and the given contents were very useful and the precision has given here is good.
ReplyDeleteRPA Training in Chennai
Jual Obat Aborsi ,
ReplyDeleteObat Aborsi ,
Cara Menggugurkan Kandungan ,
Obat Penggugur Kandungan ,
I found your this post while searching for information about blog-related research ... It's a good post .. keep posting and updating information. login to hotmail
ReplyDelete
ReplyDeletevery good article dewa poker
usefull article about "How accurate is Google Flu Trends". thanks for sharing.
ReplyDeleteData Science Training in Chennai
excellent topics gathered lots of informations,keep share your post
ReplyDeleteHadoop Training in Chennai
Thank you sharing this wonderful information. Nice Post.
ReplyDeleteTraining and placement institutes in Chennai | Training and job placement in Chennai
ReplyDeleteHello. This post couldn’t be written any better! Reading this post reminds me of my previous roommate. He always kept chatting about this. I will forward this page to him.
bigdata training institute in bangalore
Jual Obat Aborsi ,
ReplyDeleteObat Aborsi http://jualobat-aborsi.com Obat Penggugur Kandungan,
Obat Aborsi ,
Jual Cytotec Asli http://jualpilcytotecasli.com Jual Obat Aborsi ,
OBAT KLG
ReplyDeleteOBAT KLG USA
OBAT KLG USA ASLI
OBAT PEMBESAR PENIS
OBAT PEMBESAR ALAT VITAL
PEMBESAR PENIS KLG
KHASIAT KLG PILLS
Thanks for the wonderful information were given here and thanks for sharing.
ReplyDeleteAWS Training in Chennai
Jual OBAT ABORSI 082133482133 - Obat Aborsi Asli, Obat Cytotec, Obat Penggugur Kandungan, Obat Pelancar Haid, Obat Aborsi Misoprostol, Jual Obat Cytotec.Obat aborsi Bergaransi Bersih tuntas
ReplyDeletehttps://www.klinik-chionghua.com/
https://www.aborsipenggugur.com/
https://obatpenggugur-kandungan.com/
http://obatcytotecimport.com/
http://cytotecmanjur.com/
https://aborsicepat.com/
Obat Aborsi Tuntas
Obat Aborsi
Obat Aborsi Asli
Obat Aborsi Manjur
Obat Aborsi Ampuh
Obat Aborsi aman
Jual Obat Aborsi
Jual Obat Aborsi tuntas
Jual Obat Aborsi Asli
Jual Obat Aborsi Manjur
Jual Obat Aborsi Ampuh
Jual Obat Aborsi Aman
Obat Penggugur Kandungan
Jual Obat Penggugur Kandungan
Obat Cytotec
Obat Cytotec Tuntas
Obat Cytotec Asli
Jual Obat Cytotec
Jual Obat Cytotec Asli
Jual Obat aborsi Untuk Janin Kuat
Obat Aborsi Tuntas
Obat Aborsi
Obat Aborsi Asli
Obat Aborsi Manjur
Obat Aborsi Ampuh
Obat Aborsi aman
Jual Obat Aborsi
Jual Obat Aborsi tuntas
Jual Obat Aborsi Asli
Jual Obat Aborsi Manjur
Wow it is really wonderful and awesome thus it is very much useful for me to understand many concepts and helped me a lot. it is really explainable very well and i got more information from your blog.
ReplyDeleteData science training in velachery
Data science training in kalyan nagar
Data Science training in OMR
Data Science training in anna nagar
Data Science training in chennai
Data Science training in marathahalli
Data Science training in BTM layout
Data Science training in rajaji nagar
This is most informative and also this post most user friendly and super navigation to all posts... Thank you so much for giving this information to me..
ReplyDeleteDevops training in velachry
Devops training in OMR
Deops training in annanagar
Devops training in chennai
Devops training in marathahalli
Devops training in rajajinagar
Devops training in BTM Layout
Wonderful bloggers like yourself who would positively reply encouraged me to be more open and engaging in commenting.So know it's helpful.
ReplyDeletejava training in annanagar | java training in chennai
java training in marathahalli | java training in btm layout
java training in rajaji nagar | java training in jayanagar
This comment has been removed by the author.
ReplyDeleteHello! This is my first visit to your blog! We are a team of volunteers and starting a new initiative in a community in the same niche. Your blog provided us useful information to work on. You have done an outstanding job.
ReplyDeleteBest AWS Training in Chennai | Amazon Web Services Training in Chennai
AWS Training in Chennai | AWS Training Institute in Chennai Velachery, Tambaram, OMR
AWS Training in Chennai |Best Amazon Web Services Training in Chennai
AWS Training in Rajaji Nagar | Amazon Web Services Training in Rajaji Nagar
Amazon Web Services Training in OMR , Chennai | Best AWS Training in OMR,Chennai
Thanks Admin for sharing such a useful post, I hope it’s useful to many individuals for developing their skill to get good career.
ReplyDeletepython online training
python training course in chennai
python training in jayanagar
It was very encouraging to see this kind of content. Thank you for sharing.
ReplyDeleteGerman Course in Chennai
German Training in Chennai
French Class in Chennai
French Training
Selenium Course in Chennai
Hadoop Training in Chennai
iOS Training in Chennai
Learned a lot from your blog. Good creation and hats off to the creativity of your mind. Share more like this.
ReplyDeleteccna Training institute in Chennai
ccna institute in Chennai
ccna Training center in Chennai AWS Training in Chennai
Angularjs Training in Chennai
RPA Training in Chennai
good work done and keep update more.i like your informations and that is very much useful for readers.
ReplyDeleteCloud computing Training institutes in Bangalore
Cloud Computing Training in Perambur
Cloud Computing Training in Saidapet
Cloud Computing Training in Navalur
Usually, I never comment on blogs but yours is so convincing that I never stop myself to say something about it. keep updating regularly.
ReplyDeleteSpoken English in Adyar | Spoken English Classes in Palavakkam | Spoken English Classes in ECR | Spoken English Classes in Gandhi Nagar | Spoken English Training in Kasturibai Nagar | Spoken English Classes in Indira Nagar | Spoken English Classes near Adyar
This is a good post. This post give truly quality information. I’m definitely going to look into it. Really very useful tips are provided here. thank you so much. Keep up the good works.
ReplyDeleteRPA Training in Chennai
Robotics Process Automation Training in Chennai
RPA courses in Chennai
Robotic Process Automation Training
RPA course
Your blog is very interesting to read. Keep sharing this kind of worthy information.
ReplyDeleteIoT Training in Chennai | IoT courses in Chennai | Internet of Things Training in Chennai | IoT Training | IoT Training in Adyar | IoT Course in Tambram
Thanks for sharing the amazing post.It is very much informative. I am very eager to read your upcoming post.
ReplyDeletePrimavera p6 Training in Chennai
Primavera Coaching in Chennai
Primavera Course
Primavera Training
Primavera p6 Training
Primavera Training in Chennai
Primavera Training in Chennai
Learned a lot from your blog. Good creation and hats off to the creativity of your mind. Share more like this.
ReplyDeleteDigital Marketing Training in Kelambakkam
Digital Marketing Training in Karappakkam
Digital Marketing Training in Padur
Digital Marketing Training in Kandanchavadi
Digital Marketing Training in sholinganallur
thank you for sharing such a nice and interesting blog with us. i have seen that all will say the same thing repeatedly. But in your blog, I had a chance to get some useful and unique information. I would like to suggest your blog in my dude circle. please keep on updates. hope it might be much useful for us. keep on updating...
ReplyDeleteGerman Classes in Chennai
German Language Classes in Chennai
German Language Course in Chennai
German Courses in Chennai
Best german classes in chennai
German language training in chennai
Excellent post!!!. The strategy you have posted on this technology helped me to get into the next level and had lot of information in it.
ReplyDeletePHP Training Institute in Velachery
PHP Training in Velachery
PHP Training in Chennai Velachery
PHP Training in Tambaram
PHP Training in Kandanchavadi
PHP Training in Sholinganallur
Innovative thinking of you in this blog makes me very useful to learn.
ReplyDeletei need more info to learn so kindly update it.
Java Institutes in bangalore
Java Courses in Thirumangalam
Java Training Institutes in Numgambakkam
Java Training in Karapakkam
Very interesting blog. It helps me to get the in depth knowledge. Thanks for sharing such a nice blog
ReplyDeletePega Training in Chennai
Pega Course in Chennai
Pega Training Institutes in Chennai
Pega Training Institute in Chennai
Pega Course
Pega Training
Pega Certification Training
Pega Developer Training
ReplyDeleteorganic cold pressed oils
natural cold pressed oils
organic oil
natural oil
pure herbal oil
ayurvedic oil store in jaipur
ayurvedic oil
Good Post! Thank you so much for sharing this pretty post, it was so good to read and useful to improve my knowledge as updated one, keep blogging…
ReplyDeleteEthical Hacking Training Institute in Bangalore
Ethical Hacking Course in Bangalore
Ethical Hacking Training in Chennai Adyar
Ethical Hacking Training in Chennai Adyar
Ethical Hacking Course in Chennai
Ethical Hacking Training in Velachery
Really very nice blog information for this one and more technical skills are improve,i like that kind of post....
ReplyDeleteselenium training in chennai
java training in chennai
Really very nice blog information for this one and more technical skills are improve,i like that kind of post.
ReplyDeleteangularjs-Training in tambaram
angularjs-Training in sholinganallur
angularjs-Training in velachery
angularjs Training in bangalore
angularjs Training in bangalore
Hi, Your post is quite great to view and easy way to grab the extra knowledge. Thank you for your share with us. I like to visit your site again for my future reference.
ReplyDeleteJava Training in Chennai
PHP Training in Chennai
Core Java Training in Chennai
Java Training center in Chennai
PHP Training
Best PHP training in chennai
Great Post. It shows your deep understanding of the topic. Thanks for Posting.
ReplyDeleteNode JS Training in Chennai
Node JS Course in Chennai
Node JS Advanced Training
Node JS Training Institute in chennai
Node JS Training Institutes in chennai
Node JS Course
ReplyDeleteSuperb. I really enjoyed very much with this article here. Really it is an amazing article I had ever read. I hope it will help a lot for all. Thank you so much for this amazing posts and please keep update like this excellent article.thank you for sharing such a great blog with us. expecting for your.
Selenium training in chennai
Selenium training institute in Chennai
iOS Course Chennai
Digital Marketing Training in Chennai
hp loadrunner training
Loadrunner Training in Velachery
This is really too useful and have more ideas and keep sharing many techniques. Eagerly waiting for your new blog keep doing more.
ReplyDeletebest cloud computing institute in bangalore
Android Training Center in Bangalore
Android Institute in Bangalore
cloud computing training institutes in bangalore
Great Article
ReplyDeleteData Mining Projects IEEE for CSE
Final Year Project Domains for CSE
Nice Blog..
ReplyDeleteblockchain training in BTM
It is a wonderful data you offered to us I really enjoy by reading your article.
ReplyDeleteSelenium training in Chennai
Selenium Courses in Chennai
best ios training in chennai
.Net coaching centre in chennai
French Classes in Chennai
Big Data Training in Chennai
Best Android Training institute in Chennai
Android Training Institutes in Chennai
Great article with an excellent idea!Thank you for such a valuable article. I really appreciate for this great information.
ReplyDeleteSelenium Training in Chennai
selenium Classes in chennai
iOS Training in Chennai
French Classes in Chennai
Big Data Training in Chennai
SEO Training Chennai
Best seo training in chennai
nice information .am liking the blog
ReplyDeletedigital marketing courses in Bangalore With placement
digital marketing training in Bangalore
seo training in Bangalore
Thank you for the useful article. It has helped a lot. top college in Jaipur
ReplyDeleteNice and good article. It is very useful for me to learn and understand easily.
ReplyDeleteThe best college in Jaipur
Awesome post, continue sharing more like this.
ReplyDeleteGuest posting sites
Technology
VERY NICE BLOG
ReplyDeletedigital marketing courses in Bangalore With placement
digital marketing training in Bangalore
seo training in Bangalore
Thanks for one marvelous posting..
ReplyDeleteblockchain training in Marathahalli
ReplyDeleteThe blog which you have shared is more useful for us. Thanks for your information. Waiting for your more updates
German Language Course
German Courses in Coimbatore
German Courses Near Me
Learn German Course
German Language Training
Very interesting blog!!! I learn lot of information from your post. It is very helpful to me. Thank you for your fantastic post. please visit
ReplyDeleteCCTV Camera in jaipur at Rajasthan
Home security system in jaipur
Wireless Home Security System in jaipur
Realtime attendance machine in jaipur
CCTV Camera dealer in jaipur
Hikvision DVR in jaipur at Rajasthan
security system solutions in jaipur
Excellent Blog!!! Such an interesting blog with clear vision, this will definitely help for beginner to make them update.
ReplyDeleteAndroid Training in Chennai
Selenium Training in Chennai
Digital Marketing Training in Chennai
JAVA Training in Chennai
Thanks for sharing this interesting blog with us.My pleasure to being here on your blog..I wanna come beck here for new post from your site.
ReplyDeleteQtp training in Chennai
Android Training in Chennai
Selenium Training in Chennai
Digital Marketing Training in Chennai
JAVA Training in Chennai
This information is impressive. I am inspired with your post writing style & how continuously you describe this topic. Eagerly waiting for your new blog keep doing more.
ReplyDeleteGerman Classes in Chennai
Digital Marketing Training in Chennai
JAVA Training in Chennai
Selenium Course in Chennai
selenium testing training in chennai
Hello! Someone in my Facebook group shared this website with us, so I came to give it a look. I’m enjoying the information. I’m bookmarking and will be tweeting this to my followers! Wonderful blog and amazing design and style.
ReplyDeletesafety course in chennai
Try playing online gambling on the BGAOC website. great blackjack online Only here are permanent and Bosnian wins.
ReplyDelete
ReplyDeleteI have read your blog its very attractive and impressive. Nice information. It helped me alot.
organic cold pressed oils
natural cold pressed oils
organic oil
organic oil in jaipur
organic cold pressed oil in jaipur
natural oil
natural oil shop in jaipur
pure herbal oil
ayurvedic oil store in jaipur
ayurvedic oil
cloud computing training in chennai
ReplyDeleteCloud Computing Courses in Chennai
Big Data Training in Chennai
Hadoop Training in Chennai
Digital Marketing Course in Chennai
Selenium Training in Chennai
JAVA Training in Chennai
web designing course in chennai
web designing training in chennai
Very good post thanks for sharing
ReplyDeleteccna training in chennai
Very nice post here thanks for it .I always like and such a super contents of these post.Excellent and very cool idea and great content of different kinds of the valuable information's.
ReplyDeletemachine learning with python course in chennai
machine learning course in chennai
best training insitute for machine learning
Android training in velachery
PMP training in chennai
I really want to thank you for such kind of wonderful blog posted for us.I expect this kind of updation soon in your page.
ReplyDeleteSoftware testing training in chennai
Salesforce Training in Chennai
Android Training in Chennai
Digital Marketing Training in Chennai
ReplyDeletethe article is nice.most of the important points are there.thankyou for sharing a good one.
RPA course in Chennai
RPA Training Institute in Chennai
Blue Prism Training Chennai
Blue Prism Training Institute in Chennai
UiPath Courses in Chennai
rpa Training in OMR
rpa Training in Adyar
I like your post very much. I need more updates from your side. It will be very useful for my future reference and further research.
ReplyDeletePHP Training in Chennai
PHP Course in Chennai
Java Training in Chennai
German Classes in Chennai
AngularJS Training in Chennai
PHP Training in OMR
PHP Training in TNagar
Thank you for sharing your article. Great efforts put it to find the list of articles which is very useful to know, Definitely will share the same to other forums.
ReplyDeletebest openstack training in chennai | openstack course fees in chennai | openstack certification in chennai | openstack training in chennai velachery
Nice post. Thanks for sharing! I want people to know just how good this information is in your article. It’s interesting content and Great work.
ReplyDeleteThanks & Regards,
VRIT Professionals,
No.1 Leading Web Designing Training Institute In Chennai.
And also those who are looking for
Web Designing Training Institute in Chennai
Photoshop Training Institute in Chennai
PHP & Mysql Training Institute in Chennai
SEO Training Institute in Chennai
Android Training Institute in Chennai
Awesome article! You are providing us very valid information. This is worth reading. Keep sharing more such articles.
ReplyDeleteTally Course in Chennai
Tally Classes in Chennai
corporate training in chennai
Excel classes in Chennai
Tally Course in Anna Nagar
Tally Course in Velachery
Thanks For Sharing The Information The Information shared Is Very Valuable Please Keep Updating Us Time Just Went On reading The Article Aws Online Course Python Online Course Data Online Course Hadoop Online Course
ReplyDeleteThanks For Sharing The Information The Information shared Is Very Valuable Please Keep Updating Us Time Just Went On reading The Article Python Online Training Aws Online Course DataScience Online Course Devops Online Course
ReplyDeleteI think this is a great site to post and I have read most of contents and I found it useful for my Career .Thanks for the useful information. For any information or Queries Comment like and share it.
ReplyDeletelg mobile service chennai
lg mobile repair
Hello, I read your blog occasionally, and I own a similar one, and I was just wondering if you get a lot of spam remarks? If so how do you stop it, any plugin or anything you can advise? I get so much lately it’s driving me insane, so any assistance is very much appreciated.
ReplyDeleteAndroid Course Training in Chennai | Best Android Training in Chennai
Selenium Course Training in Chennai | Best Selenium Training in chennai
Devops Course Training in Chennai | Best Devops Training in Chennai
Really awesome blog. Your blog is really useful for me
ReplyDeleteRegards,
Best Selenium Training Institute in Chennai | Selenium Course in Chennai
The knowledge of technology you have been sharing thorough this post is very much helpful to develop new idea.
ReplyDeletePython training in Chennai | Python training Institute in Chennai
Thanks for the valuable information and insights you have so provided here... Buy Google Reviews Places,
ReplyDeleteYou Are doing a great job. I would like to appreciate your work for good accuracy
ReplyDeleteBest Data Science Training in chennai
I have read your blog it is very helpful for me. I want to say thanks to you. I have bookmark your site for future updates. Buy Business Google Reviews,
ReplyDeleteI have read your blog it is very helpful for me. I want to say thanks to you. I have bookmark your site for future updates. Buy Business Google Reviews,
ReplyDeleteThanks for sharing detail this blog...any student more information visit here
ReplyDeleteJava Training in Delhi
Yahoo E-Mail Technical Support
ReplyDeleteYahoo E-Mail Technical Support Is provide support on your all yahoo mail's technical issue which you are facing in your
yahoo E-mail. If you are facing any Technical issue in your yahoo E-mail then call +1800-284-6979 yahoo E-mail technical support officer
and get your issu resolved qickly . feel free to call us.
Yahoo E-Mail Technical Support
And indeed, I’m just always astounded concerning the remarkable things served by you. Some four facts on this page are undeniably the most effective I’ve had.
ReplyDeleteJava Training in Chennai |Best Java Training in Chennai
C C++ Training in Chennai |Best C C++ Training Institute in Chennai
Data science Course Training in Chennai |Best Data Science Training Institute in Chennai
RPA Course Training in Chennai |Best RPA Training Institute in Chennai
AWS Course Training in Chennai |Best AWS Training Institute in Chennai
Incredible Blog!!! Thanks for sharing this data with us... Waiting for your New Updates.
ReplyDeleteSpoken English Class in Madurai
best spoken english class in madurai
Spoken English Class in Coimbatore
Best Spoken English Classes in Coimbatore
Java Training in Bangalore
Python Training in Bangalore
IELTS Coaching in Madurai
IELTS Coaching in Coimbatore
Java Training in Coimbatore
Obat Menggugurkan Kandungan
ReplyDeleteCara Menggugurkan Kandungan
Obat Telat Datang Bulan
Ciri Obat Cytotec Asli Dan Palsu
Cara Menggugurkan Janin Dengan Nanas Muda
Obat Gynaecosid
Obat Aborsi Jogja
Cara Menggugurkan Kandungan Dengan Kunyit
Obat Aborsi Bandung
Obat Aborsi Lampung
very nice post and its very useful to me and i have to seen some online weblinks.about python traing if u want any another information plz check the below link.
ReplyDeletepython online training
aol email problems , you are using Aol email And facing any problem in your Aol email then call official Aol email Toll Free Number 1800-684-5649. And talk with aol email help support officer for all your aol mail problem . feel free to call 24x7 around o clock.
ReplyDeleteaol email problem
ReplyDeleteAmazing post!!! This is very helpful for gain my knowledge and the author putting in the effort was too good. Great explanation in this topic...
Embedded System Course Chennai
Embedded Training in Chennai
Excel Training in Chennai
Corporate Training in Chennai
Oracle Training in Chennai
Unix Training in Chennai
Power BI Training in Chennai
Embedded System Course Chennai
Embedded Training in Chennai
Awesome post. After reading your blog I am happy that i got to know new ideas; thanks for sharing this content.
ReplyDeleteIELTS Classes in Mumbai
IELTS Coaching in Mumbai
IELTS Mumbai
Best IELTS Coaching in Mumbai
IELTS Center in Mumbai
Spoken English Classes in Chennai
IELTS Coaching in Chennai
English Speaking Classes in Mumbai
aol mail problem, you are using Aol mail And facing any glitch in your Aol mail then call official Aol Mail Toll Free Number 1800-684-5649. And talk with aol mail technical support officer for all your aol mail problem . feel free to call 24x7 around o clock. aol mail problem
ReplyDelete
ReplyDeleteYou might comment on the order system of the blog. You should chat it's splendid. Your blog audit would swell up your visitors. I was very pleased to find this site.I wanted to thank you for this great read!!
www.excelr.com/digital-marketing-training
digital marketing course
Great blog. Thanks for sharing post.
ReplyDeletesafety course in chennai
nebosh course in chennai
Thanks for sharing post.
ReplyDeleteiosh safety course in chennai
safety course in chennai
iosh course in chennai
Good Post! Thank you so much for sharing this pretty post, it was so good to read and useful to improve my knowledge as updated one, keep blogging
ReplyDeleteBig Data Hadoop Training in electronic city
Thank you for this sharing.
ReplyDeleteCheck out the best entertainment unit
it's really a piece of new information to me, I learn more from this blog, I want to learn more from this blog, keep on it doing, I eagerly waiting for your updates, Thank you!!!
ReplyDeleteBest Aviation Academy in Chennai
Best Air hostess Training in Chennai
Pilot Training in Chennai
Airport Ground staff Training in Chennai
Airport Flight Dispatcher Trainee in Chennai
RTR - Aero Training in Chennai
Cabin Crew Training in Chennai
Aviation Academy in Chennai
Aviation training institute in Chennai
Aviation Course Training in Chennai
Ground staff Training institute in Chennai
Airhostess Training institute in Chennai
Cabin Crew Course
PRIVATE PILOT LICENCE (PPL) Training in Chennai
COMMERCIAL PILOT LICENCE (CPL) Training in Chennai
I was very pleased to find this web-site.I wanted to thanks for your time for this wonderful read!! I definitely enjoying every little bit of it and I have you bookmarked to check out new stuff you blog post.
ReplyDeleteAplikasi Dapodikdasmen Terbaru
Sidaring
The article is so informative. This is more helpful for our
ReplyDeletesoftware testing training courses
selenium testing training
software testing training institute
Thanks for sharing.
Thanks alot for the blog!!!!
ReplyDeleteLearn Digital Marketing Course Training and Placement Institute in Chennai
Thanks for sharing this awesome content
ReplyDeletetop 10 biography health benefits bank branches offices in Nigeria dangers of ranks in health top 10 biography health benefits bank branches offices in Nigeria latest news ranking biography
Digital Marketing Courses in Bangalore
ReplyDeleteIf your looking for Digital Marketing Course in Bangalore, then your search ends with ExcelR.
Learn the Online Digital Marketing Course, from the best in industry with live mentored sessions and Live porjects.
Become the expert in modules like SEM, SEO, Adwords, Analytics & much more
Want more information about Digital Marketing Course, then visit our website
Website
https://www.excelr.com/
URL
https://www.excelr.com/digital-marketing-training-in-bangalore
YouTube
https://www.youtube.com/channel/UCF2_gALht1C1NsAm3fmFLsg
Looking for natural medicine to flu without any side effect Dr Williams is the best because it has no side effect, After my mom being diagnosed of flu in 2010, I have used numerous medicine on her with no improvement. she spent most of the summer in the hospital. I remember she feeling abandoned and terrified of the many injection needles that seemed necessary to keep her calm. All Western Medicine used in the past did not have any noticeable difference,one day as i was going through the internet i came across so many people with different disease testifying about Dr Williams herbal remedies,i ordered for it on line,which i receive within 4 days, my mom started using Dr Williams Herbal Medicine,and now she is completely cured from flu , his medicine is a permanent cure to flu , for more info contact (drwilliams098675@gmail.com for advice and for his product
ReplyDeleteLooking for natural medicine to flu without any side effect Dr Williams is the best because it has no side effect, After my mom being diagnosed of flu in 2010, I have used numerous medicine on her with no improvement. she spent most of the summer in the hospital. I remember she feeling abandoned and terrified of the many injection needles that seemed necessary to keep her calm. All Western Medicine used in the past did not have any noticeable difference,one day as i was going through the internet i came across so many people with different disease testifying about Dr Williams herbal remedies,i ordered for it on line,which i receive within 4 days, my mom started using Dr Williams Herbal Medicine,and now she is completely cured from flu , his medicine is a permanent cure to flu , for more info contact (drwilliams098675@gmail.com for advice and for his product
ReplyDeleteLooking for natural medicine to flu without any side effect Dr Williams is the best because it has no side effect, After my mom being diagnosed of flu in 2010, I have used numerous medicine on her with no improvement. she spent most of the summer in the hospital. I remember she feeling abandoned and terrified of the many injection needles that seemed necessary to keep her calm. All Western Medicine used in the past did not have any noticeable difference,one day as i was going through the internet i came across so many people with different disease testifying about Dr Williams herbal remedies,i ordered for it on line,which i receive within 4 days, my mom started using Dr Williams Herbal Medicine,and now she is completely cured from flu , his medicine is a permanent cure to flu , for more info contact (drwilliams098675@gmail.com for advice and for his product
ReplyDeleteThanks for sharing this,German language institute in Jaipur. We are offering the best German language classes in Jaipur. Join our best designed German Course in Jaipur
ReplyDeleteThanks for sharing this,German language institute in Jaipur. We are offering the best German language classes in Jaipur. Join our best designed German Course in Jaipur.
ReplyDeletegerman language institute in jaipur
I really appreciate the kind of topics you post here. Thanks for sharing us a great information that is actually helpful. Good day! seo analysis
ReplyDeleteWonderful Tutorial, thanks for putting this together! This is obviously one great post. Thanks for the valuable information.
ReplyDeleteThanks for share your blog here . Wethersfield taxi near me
ReplyDeleteThanks for share your blog here . Taxi Beacon Fall Ct
ReplyDeleteI think this is one of the most significant information for me. And i’m glad reading your article. But should remark on some general things, The web site style is perfect, the articles is really great : D. Good job, cheers Click here
ReplyDeleteI think this is one of the most significant information for me. And i’m glad reading your article. But should remark on some general things, The web site style is perfect, the articles is really great : D. Good job, cheers.
ReplyDeletepool screen repair fort pierce
Hi, This is nice article you shared great information i have read it thanks for giving such a wonderful Blog for reader.
ReplyDeletetree service lantana
You have a good point here!I totally agree with what you have said!!Thanks for sharing your views...hope more people will read this article!!! patio screen repair port st lucie
ReplyDelete
ReplyDeleteVery well written article thanks for posting this amazing article with us keep growing and keep hustling
Selenium course in chennai
best selenium training institute in chennai
best selenium training in chennai
selenium training in chennai omr
selenium training in omr
big data course in chennai
big data hadoop training in chennai
big data course in chennai
Very nice bro, thanks for sharing this with us. Keep up the good work and Thank you for sharing information screen enclosure repair treasure coast fl
ReplyDelete