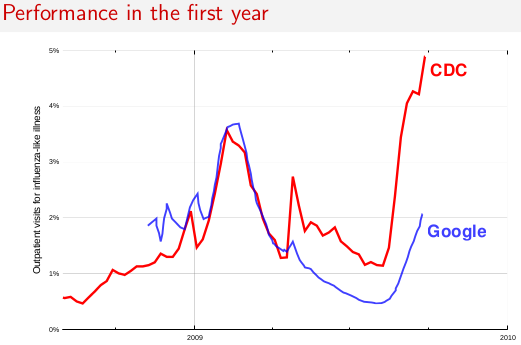
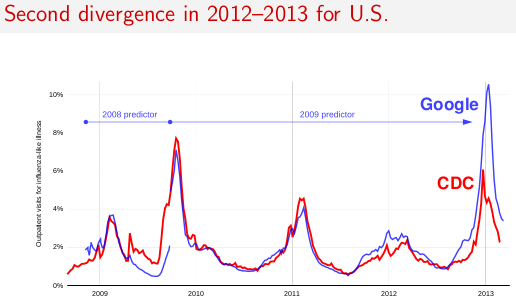
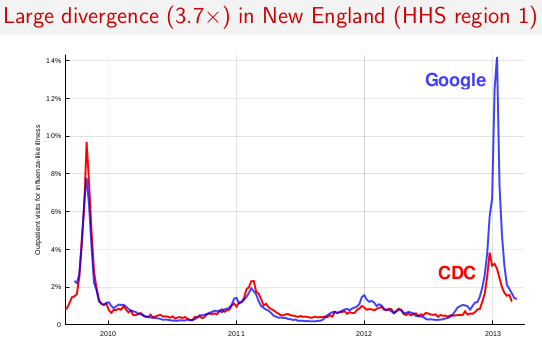
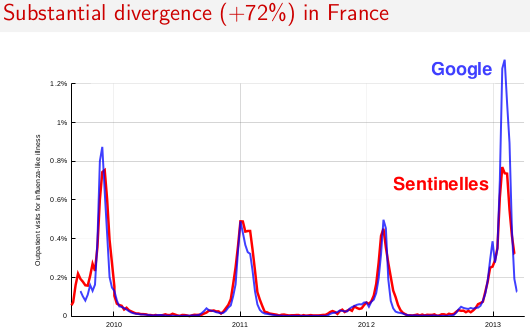
Update March 14, 2013:
In 2012–13, Google Flu Trends did not successfully track the target flu indexes in the U.S., France, or Japan. Here are my slides from a talk at the Children's Health Informatics Program (March 14, 2013).
Why this happened is a mystery. Google has said they will present their own view some time this fall. I think the divergence suggests that one needs to be careful about trusting these kinds of machine-generated estimators, even when they work well for three years in a row. It can be hard to predict when they will fall down. (And without an underlying index that is still measured, you might never know when it has stopped working.)
I did an interview with WBUR's CommonHealth blog
in January and again
in February, and
spoke on the radio in January.